2.1. 基本语法
我们日常生活中需要处理的纸质文档不断向web网页进行迁移,比如,门户网站的新闻、在线填写提交的保险单、购物网站的商品目录等等。无论何种形式的文档,文档 结构(structure)用于帮助读者理解文档所要传达的信息以及在整个文档中进行章节等的快速定位:以报纸上的新闻为例,一则新闻通常由一个大字标题、一些文本以及可能存在的图片组成;如果新闻内容比较长,人们会使用次级标题来进行相对独立章节的划分。在线浏览的新闻网页同样具有类似的文档结构。HTML的主要作用就是进行文档结构的描述,划分文档中的内容以进行合理的信息组织。除此之外,HTML 4.01还可以用于定义文档中的某些内容的显示 样式(style),如某段文本的颜色、字体等。
也就是说,HTML 4.01讨论如何定义内容在网页中的组织和显示。
2.1.1. 元素
为了做到这一点,HTML引入了 元素(element)的概念:元素是HTML页面的基本组成单元,元素由 标签(tag)和内容组成。
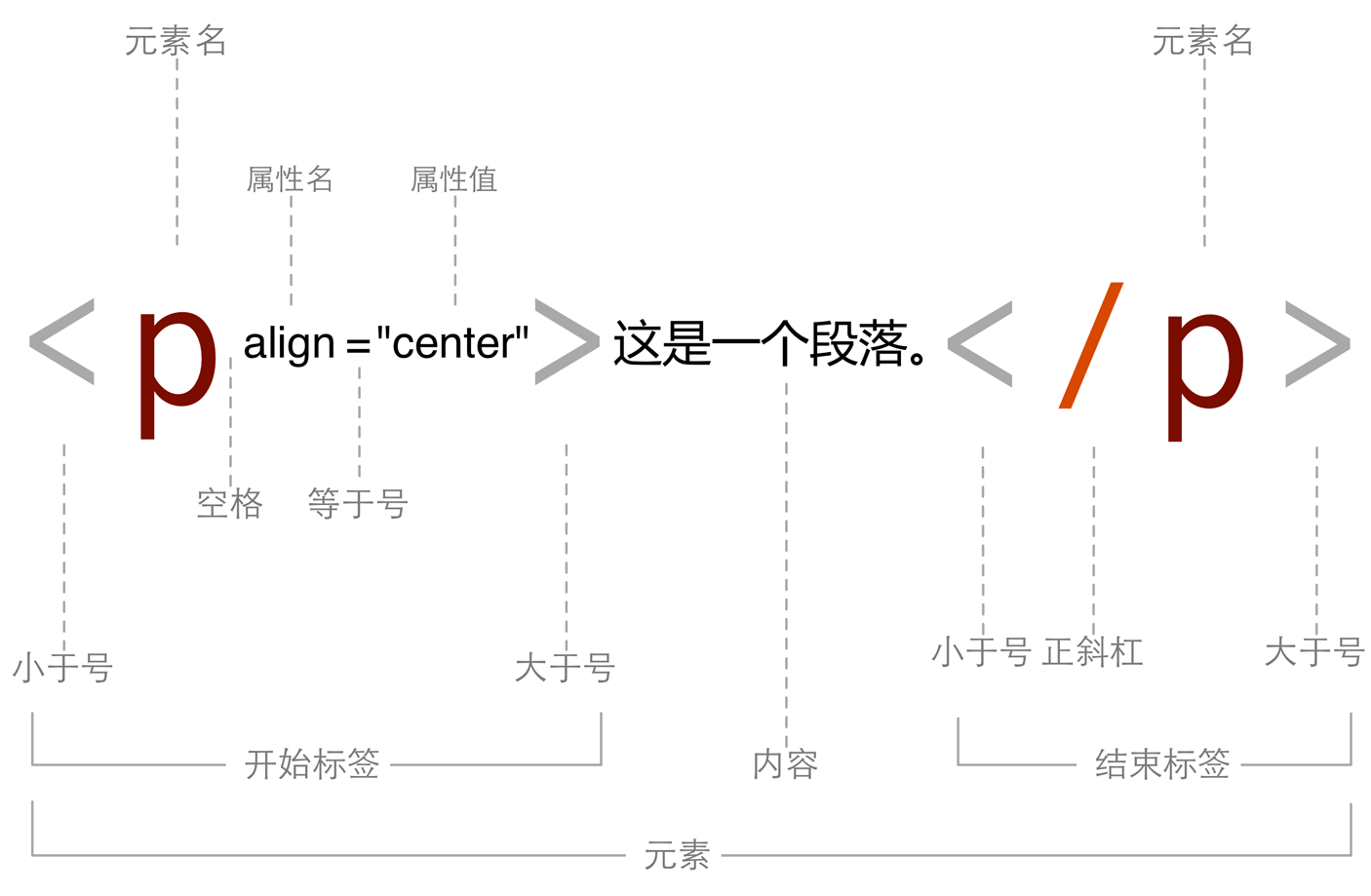
<p align="center">这是一个段落。</p>
以上HTML代码在网页中代表一个居中显示的段落,段落文本是“这是一个段落。”,其中,
- <p>、</p>是两个
标签,标签使用一对尖括号(<>)包含起来,分为开始标签(opening tag)和结束标签(closing tag); - 开始标签可以包含一组或多组
属性(attribute),align="center" 是一组属性,其中 align 是属性名,center 是属性值,属性名和属性值之间使用等号 “=” 连接,两组以上属性之间使用空格分隔,属性不是必须的; - 结束标签的标志是标签开始符号 “<” 后有一个斜杠 “/”,结束标签没有属性;
- 开始和结束标签之间的文本称为
内容(content); - 开始标签、结束标签及其中包含的内容这个整体被称为
元素,在一些资料中,元素和标签通常被混用,严格区分两者的概念将有利于问题的表述。 - 开始和结束标签去掉 “<”、“>”、“/” 等字符剩余的部分,被称为
元素名,元素名表明元素的用途,比如 p 说明这是一个段落。属性是对元素用途之外附加的额外信息,开始标签中如果存在属性,则第一个属性和元素名之间需要使用一个空格分隔。
HTML元素的构成
 提示:熟练掌握以上这些概念将非常有助于理解以后的内容,可以通过本节最后的练习巩固这些概念。
提示:熟练掌握以上这些概念将非常有助于理解以后的内容,可以通过本节最后的练习巩固这些概念。
元素名和属性名是字母和数字的序列,以字母开始,属性值通常使用一组 ""(英文半角双引号)或 '' (英文半角单引号)包含起来。除了一些 属性值特例(请在链接文档中搜索“case-sensitive”) 外,HTML的元素名、属性名、属性值不区分大小写,尽管如此,由于大写英文字符对阅读可能带来一些视觉障碍,建议在元素名、属性名书写时全部使用小写。
HTML 之所以被称为 标记语言 正是因为它比纯文本文件增加了元素(或标签)这种标记的概念。
2.1.2. 布尔属性
有些属性可能没有属性值,此类属性称为 布尔属性(boolean attribute),这些属性通常有表示元素 是否 具有某方面特性的 判断 意味:当一个元素具有某方面属性,则设置该属性,否则不设置,在其设置某布尔属性时,属性名和属性值是一致的。
<option value="1" selected="selected">选项1</option>
以上HTML代码表示一个被选中的选项(本节中的一些示例元素将在后面的章节中详细介绍)。其中 selected="selected" 即是一个布尔属性,表明该选项是选中的,如果该选项未被选中,则option元素表示为:
<option value="1">选项1</option>
即需要从元素中移除 selected="selected" 这对布尔属性。
处于选中状态的option元素中,属性值可以省略,即表示为:
<option value="1" selected="selected">选项1</option>
尽管如此,为了在所有属性中保持统一,我们建议在书写代码时不省略相关布尔属性的属性值。
2.1.3. 空元素
有些元素不需要结束标签,这些元素被称为 空元素(empty element 或 void element),很明显,一个元素如果是空元素意味着该元素不需要包含任何内容(即开始和结束标签之间的部分)。例如,我们需要在段落内插入一个换行,我们可以这样做:
<p>
段落内的第一行
<br />
段落内的第二行
</p>
其中,<br />即是一个空元素,因为此处我们仅仅需要的是一个段落内的换行标志,所以该元素不包含任何内容。
可以认为空元素只有开始标签省略了结束标签,另一种理解方式是空元素不需要结束标签,所以,可以在空元素标签的大于号前加上一个空格再一个正斜杠用于表明该元素已经结束。虽然空格和正斜杠不是必须的,但我们建议书写代码时使用它们以使得代码显得更加规范。
2.1.4. 最简合法文档
在了解完相关概念之后,我们来看一个相对完整的HTML文档:
<html>
<head>
<title>test document</title>
</head>
<body>
<!-- content goes here -->
</body>
</html>
以上文档中,元素 html 和 head 的开始和结束标签之间的内容并不是纯文本,而是另外的一些HTML元素,这种一个元素包含另外一个或一些元素的现象称为元素 嵌套(nesting)。嵌套的原则是先出现开始标签的元素后出现结束标签,如上例中,head 元素嵌套 title 元素,head 元素的开始标签 <head> 先于 title 元素的开始标签 <title> 出现,那么 head 元素 的结束标签 </head> 要后于 title 元素的结束标签 </title> 出现;如果 </head> 先于 </title> 出现,则是一种嵌套错误,head 元素没有完全包含 title 元素的整体。
在整个文档中,嵌套使得元素呈现出一种层次关系,我们在刚开始编写 HTML 代码时,为了使得代码更利于阅读,可以通过换行、缩进等方式将这种嵌套关系体现出来(参考上面代码中不同元素的排列方式)。
换行(使用 Enter 键键入的换行符)、缩进(使用 Tab 键键入的制表符或 Space 键键入的空格符)意味着在 HTML 源代码中会出现一些竖直方向或水平方向的空白区域,如果这些空白区域出现在 body 元素及其所包含的其它可见元素中,在浏览器中查看网页时这些空白区域将会如何显示?答案是连续出现的多个空白区域会被收缩成一个空格符。如
<body>
a
b
c
</body>
上面的 HTML 代码中,body 元素的开始结束标签中的内容里出现了 2 次换行,第 2 行字符 b 之前有两个空格,而第 3 行字符 c 之前有两个制表符。但是,在实际的浏览器窗口中查看时,网页上显示的是出现在一行的“a b c”三个字符,每个字符间只显示一个空格,即
我们通常称本小节开始的 HTML 文档是一个 最简合法HTML文档,“合法”是合乎 语法(syntax,类似于英语等自然语言,标记语言或其它程序设计语言也都有自己的语法),尽管 HTML 对于语法要求非常不严格,浏览器对于 HTML 语法的解析也非常灵活,我们还是从逻辑上对一个最简单的 HTML 文档作出以下语法上的要求:
- HTML 文档必须使用 html 作为 根元素 (root element),即其它元素都应包含在 html 元素的开始和结束标签之间
- html 元素必须包含一个 head 元素和一个 body 元素
- head 元素中必须包含一个 title 元素
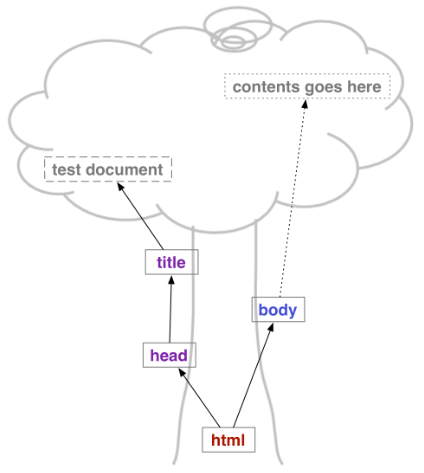
元素嵌套形成的层次关系使得整个文档中的元素呈现为一种 树 状结构(如下图所示),上述最简合法 HTML 文档语法要求中 根 元素的概念正是由此引申而来的。图中,箭头表示包含关系;实线方框表示元素,虚线方框表示文本或注释,它们都是树的 节点;我们可以称 title 是 head 的子节点,head 是 title 的父节点,又由于它们又都是元素,我们可以也可以说 title 是 head 的子元素,head 是 title 的父元素。
最简合法HTML文档树
另外,如果 A 元素包含 B 元素,我们可以称 A 元素为 B 元素的 容器。html 元素是一个文档中所有其它元素的容器,一般情况下,它直接包含 head 和 body 子元素,这两个元素把整个 html 文档划分为两个部分:其中,作为 头部 的 head 元素用于定义文档的相关信息,而实际在浏览器中显示的内容都应该包含在作为 主体 的 body 元素的开始和结束标签之内。
2.1.5. 字符引用
在上面元素的相关概念中,我们注意到 HTML 占用了一些字符,如标签的开始和结束符号 “<” 和="" “="">”,这意味着浏览器遇到这些符号时会认为它们是一个标签的开始和结束,而不会尝试把它们直接显示在网页上。为了在网页中直接显示这些 HTML 中预留的字符,需要使用字符引用(character reference),这是一种在网页中引用任何字符的机制。
字符引用有两种形式:
- 数字字符引用(Numeric Character reference, NCR)
- 字符实体引用(Character Entity Reference)
数字字符引用以符号“&”开始,以符号“;”结束,中间是以“#”开始的十进制或十六进制数,其中十六进制数需以字符“x”开始,即可概括为两种形式:
- &#D;
- &#xH;
其中 D 为一个十进制数,H 为一个十六进制数,可以称这些数字为引用编号。数字字符引用中的任何字符都不区分大小写。
举例:
< < <<br />
å å å<br />
И Й К<br />
❤ ☯ ☎<br />
欠 次 欢<br />
ᇢ ᇣ ᇤ<br />
む め も<br />
😁 🚀 🍎
å å å
И Й К
❤ ☯ ☎
欠 次 欢
ᇢ ᇣ ᇤ
む め も
😁 🚀 🍎
(注:例子中最后一行的三个字符是常用的 emoji [1][2]符号,在某些浏览器中可能因为缺乏相应字型不能正常显示)
可以看出,只要知道相应编号,字符引用的方式可以输入任何字符。
但是,由于引用编号非常难以记忆,所以,通常使用的字符引用是字符实体引用。字符实体引用的形式是使用一个便于记忆具有一定含义的名称来代替数字字符引用中以“#”开始的数字部分。
HTML 中定义了 252 个命名字符实体,其中 HTML 预留字符的字符实体有:
| 字符 | 字符实体引用 | 数字字符引用 | 描述 | HTML 保留字符原因 |
|---|---|---|---|---|
| " | " | " | 双引号(double quotation mark) | 属性值开始和结束字符 |
| & | & | & | 连接符(ampersand) | 字符引用的开始字符 |
| ' | ' | ' | 单引号(apostrophe) | 属性值开始和结束字符 |
| < | < | < | 小于号(less-than sign) | 标签的开始字符 |
| > | > | > | 大于号(greater-than sign) | 标签的结束字符 |
另外三个常用的字符实体引用:
| 字符 | 字符实体引用 | 数字字符引用 | 描述 |
|---|---|---|---|
| © | © | © | 版权所有(copyright symbol) |
| ® | ® | ® | 注册商标(registered sign) |
| |   | 空格(no-break space) |
由于 HTML 源代码中连续出现的多个空白区域会被收缩成一个空格符,所以如果希望在页面中出现连续多个空格,可以在源代码中连续插入多个字符实体引用 。
在各种标记语言和程序设计语言中,都有转义序列(escape sequence)的概念,字符引用可以认为是 HTML 中的转义序列,而字符引用的开始符号“&”被称为转义字符(escape character)。
推荐两个关于字符引用的网站:Unicode 字符百科(http://unicode-table.com/cn/)和 EntityCode(http://www.entitycode.com/)。
2.1.6. 注释
上面提供的最简合法 HTML 文档的 body 元素中包含的内容被称为注释(comment)。HTML 注释为网页设计人员服务,不会显示在浏览器中上,和最终浏览者无关。它一般是 HTML 代码片段作用的描述,作用是使得网页设计人员后期可以对代码进行快速回顾(review),或者是使得协同开发的其他网页设计人员快速理解代码。
注释以字符串 “<!--” 开始,以字符串 “-->” 结束,包含在这两个字符串之间的部分即是要注释内容,注释内容中可以出现换行。
如:
<!--
banner in homepage
2014.10.30
-->
主页横幅的 HTML 代码
由于注释是针对源代码而言的,所以字符引用在注释中不起作用,如:
<!-- < < © © > > -->
出现在注释中的字符引用
2.1.7. HTML 头元素
head 元素是其它头部元素的容器,在 head 元素中包含的其它元素用于说明网页的标题、提供网页元信息、声明当前网页引用的其它文件等,这些必要的元素在页面中是不可见的。
2.1.7.1. title 元素
如上文所说,title 元素是最简合法 HTML 文档中 head 元素中必需包含的元素,它用于说明网页的标题,其开始和结束标签中包含的文本将出现在以下位置(不同浏览器可能对应不同的功能):
- 浏览器标题栏
- Windows 系统任务栏
- 收藏网页(或添加书签)时收藏(或书签)的名称
- 搜索引擎中搜索结果的名称
- 创建快捷方式时快捷方式的名称 等
这些位置的占用的空间相对较小,所以,使用 title 指定网页标题时虽然简单,但由于标题对网页内容有着重要的提示作用,所以在指定标题时不能太随意,指定的文本应该简洁概括网页的主要内容,同时不该出现太多装饰作用的符号或字符,否则可能造成用户费解。
<title>Google</title>
<title>欢迎来到微博 微博-随时随地发现新鲜事</title>
<title> ★★★★★ XXX的个人主页 ★★★★★ </title>
请体会以上三个网页标题的优劣。
2.1.7.2. meta 元素
另外一个 head 元素中包含的重要元素是 meta 元素。meta 是一个前缀,翻译为“元”(台湾译为“后设”),是一个哲学词汇[3][4],是“关于什么的什么”的意思,在此处应该指元数据 metadata,即“关于数据的数据”,作为一个元素包含在 head 元素中指关于当前页面的一些概要或者设置信息,比如针对搜索引擎和更新频度等的描述和关键词等。
通过一些实际的应用可能更容易了解这个抽象的元素,比如:
<meta name="keywords" content="NBA,NBA季前赛,NBA十佳球,NBA中国赛,NBA常规赛,NBA中国赛,NBA打架,NBA总决赛,NBA直播" />
<meta name="description" content="这是新浪竞技风暴 NBA 专题首页。" />
<meta name="author" content="Zhang Zhaopu, cumtzzp@163.com" />
<meta name="robots" content="none" />
从以上这组 meta 元素可以看出,meta 元素是一个空元素,每个 meta 元素都是使用 name 和 content 这两个属性来为网页指定成对出现的一组信息。第一个 meta 元素用于告诉搜索引擎当前网页的关键字是什么,如你所看到的,由于网页设计人员会将非常热门的关键字都放在 content 属性之中,这其实可能是针对搜索引擎的一种欺骗,所以目前主流搜索引擎都不会再将这种设置作为某网页关键字判断的唯一依据[5][6];参考第一个 meta 元素,可以很容易知道第二、三个 meta 元素的含义,它们分别用于指定网页的描述信息和网页的作者,即 name 属性的属性值用于指定 meta 元素要指定哪方面的信息,而 content 属性的属性值用于指定对应方面的内容;最后一个 meta 元素相对特殊一些,它用于告诉搜索机器人(robots)需要索引的页面有哪些,其 content 属性值的默认值是 all ,即允许搜索引擎索引当前页面并可以继续通过当前网页中的链接索引其它网页,如果希望搜索引擎忽略当前网页以及当前网页中链接的其它网页,则可以将 content 属性值设置为 none,关于搜索机器人其它更详细的设置可以参考 附录3 。
meta 元素的 content 属性还可以和它的另外一个属性 http-equiv 搭配用于声明和 HTTP 头信息 等价 的(equivalent)设置信息,通常被用于控制浏览器某方面的行为。最常见的 meta 元素的 http-equiv 属性设置是:
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
该设置用于说明当前网页是一个使用 gb2312 编码的基于 文本 的 HTML 文档。其中,“text/html” 是 HTML 网页 的 互联网媒体类型(Internet Media Type)。而 charset 是 字符集 的意思,字符集的不正确指定可能导致网页中的字符出现 乱码 ,可以通过浏览器软件的“视图(或显示)——编码(或文本编码)”菜单呈现的编码列表子菜单切换当前页面的字符集。对于简体中文网页设计人员来说,GB2312、UTF-8 是比较常用的字符集,其中后者包含的字符更多、适应范围更广,请参考 附录4 进一步了解字符编码。需要注意的是,不包含在指定字符集中的字符在网页上是无法正常显示的;但无论采取何种字符集设置,前面提到的字符引用插入的字符都是可以正常显示在网页上的。
另外一个偶尔会遇到的 http-equiv 设置的形式如下:
<meta http-equiv="Refresh" content="5; url=http://sm.cumt.edu.cn" />
该设置会使得当前网页在 5 秒后自动转向(刷新)到 http://sm.cumt.edu.cn 。
head 元素中可能包含的其它元素在以后的章节中会逐渐涉及到。